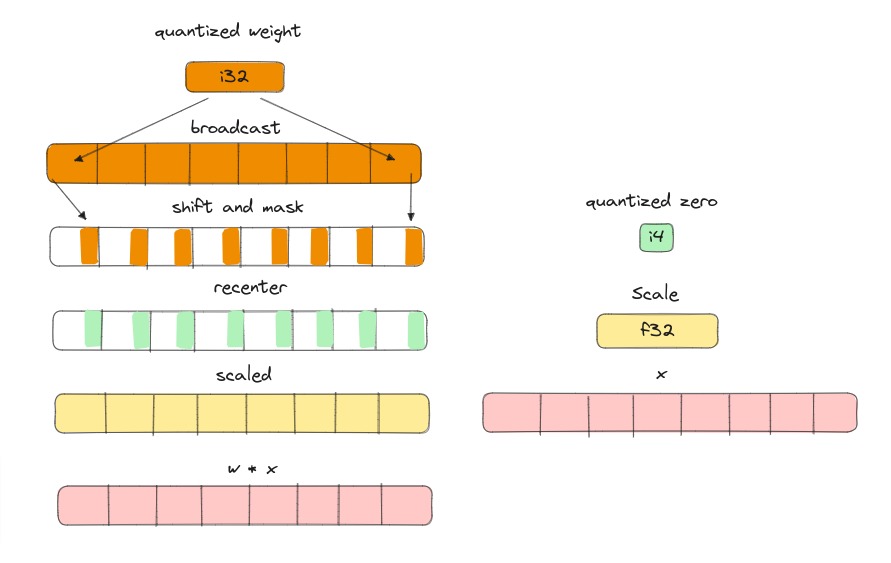
what
An one-shot weight quantization method.
features
- 2/3/4 bits quantization
- a 3-bit quantized matrix full-precision vector product CUDA kernel
- optimized for OPT-175B running on 1xA100 or 2xA6000
- on the A100, e.g. 1.9x → 3.25x generation speedup for OPT-175B
- may thus yield suboptimal performance on smaller models or on other GPUs
- activated via
--faster-kernel
- optimized for OPT-175B running on 1xA100 or 2xA6000
properties
- Works really slow on CPU (for CPU, use GGLM or GUFF)
- strangely bad performance on 7B models ^7b67a2
- fixed by GPTQ-for-LLaMa’s
--act-orderand--true-sequential
- fixed by GPTQ-for-LLaMa’s
Dequantize