Cite
Geva, Mor, et al. Transformer Feed-Forward Layers Are Key-Value Memories. arXiv:2012.14913, arXiv, 5 Sept. 2021. arXiv.org, http://arxiv.org/abs/2012.14913.
Metadata
Title: Transformer Feed-Forward Layers Are Key-Value Memories Authors: Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy Cite key: geva2021
Links
Abstract
Feed-forward layers constitute two-thirds of a transformer model’s parameters, yet their role in the network remains under-explored. We show that feed-forward layers in transformer-based language models operate as key-value memories, where each key correlates with textual patterns in the training examples, and each value induces a distribution over the output vocabulary. Our experiments show that the learned patterns are human-interpretable, and that lower layers tend to capture shallow patterns, while upper layers learn more semantic ones. The values complement the keys’ input patterns by inducing output distributions that concentrate probability mass on tokens likely to appear immediately after each pattern, particularly in the upper layers. Finally, we demonstrate that the output of a feed-forward layer is a composition of its memories, which is subsequently refined throughout the model’s layers via residual connections to produce the final output distribution.
Notes
From Obsidian
(As notes and annotations from Zotero are one-way synced, this section include a link to another note within Obsidian to host further notes)
Transformer-Feed-Forward-Layers-Are-Key-Value-Memories
From Zotero
(one-way sync from Zotero)
Annotations
Highlighting colour codes
Link to original
- Note: highlights for quicker reading or comments stemmed from reading the paper but might not be too related to the paper
- External Insight: Insights from other works but was mentioned in the paper
- Question/Critic: questions or comments on the content of paper
- Claim: what the paper claims to have found/achieved
- Finding: new knowledge presented by the paper
- Important: anything interesting enough (findings, insights, ideas, etc.) that’s worth remembering
From Zotero
(one-way sync from Zotero) Imported: 2024-12-04
Note | View in local Zotero: page 1
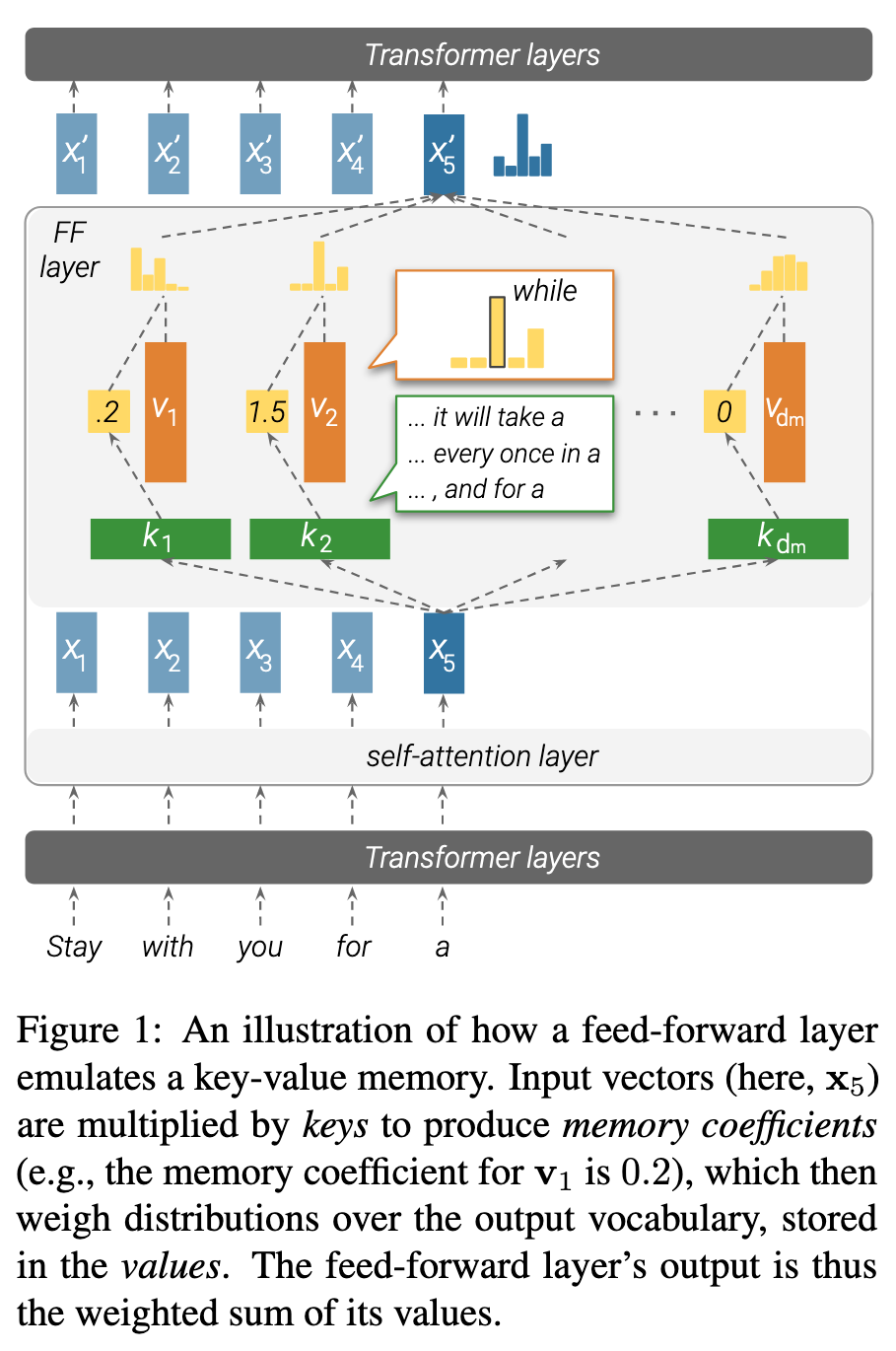
Note | View in local Zotero: page 2
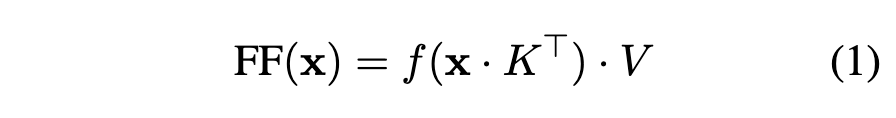
Note | View in local Zotero: page 2
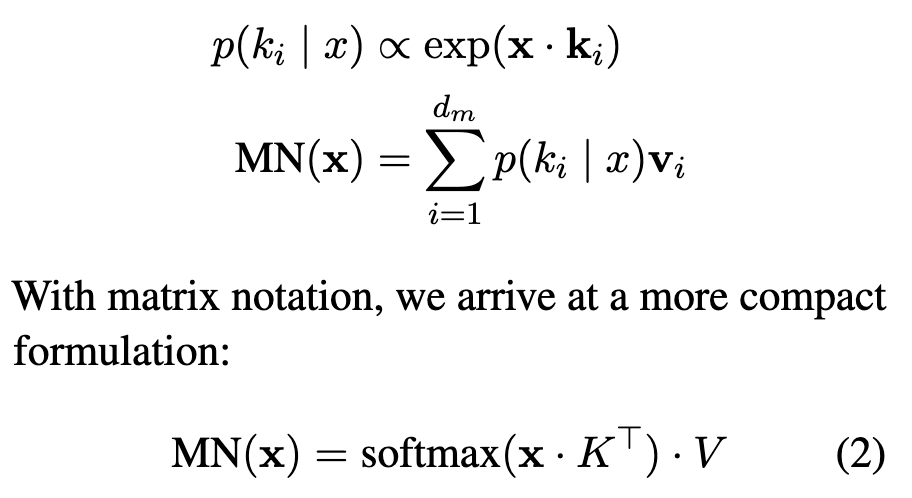
Claim | View in local Zotero: page 2
“We conjecture that each key vector ki captures a particular pattern (or set of patterns) in the input sequence (Section 3), and that its corresponding value vector vi represents the distribution of tokens that follows said pattern (Section 4).”
Important | View in local Zotero: page 6
“the layer-level prediction is typically not the result of a single dominant memory cell, but a composition of multiple memories.”
Important | View in local Zotero: page 6
“We further analyze cases where at least one memory cell agrees with the layer’s prediction, and find that (a) in 60% of the examples the target token is a common stop word in the vocabulary (e.g. “the” or “of”), and (b) in 43% of the cases the input prefix has less than 5 tokens.”
Important | View in local Zotero: page 7
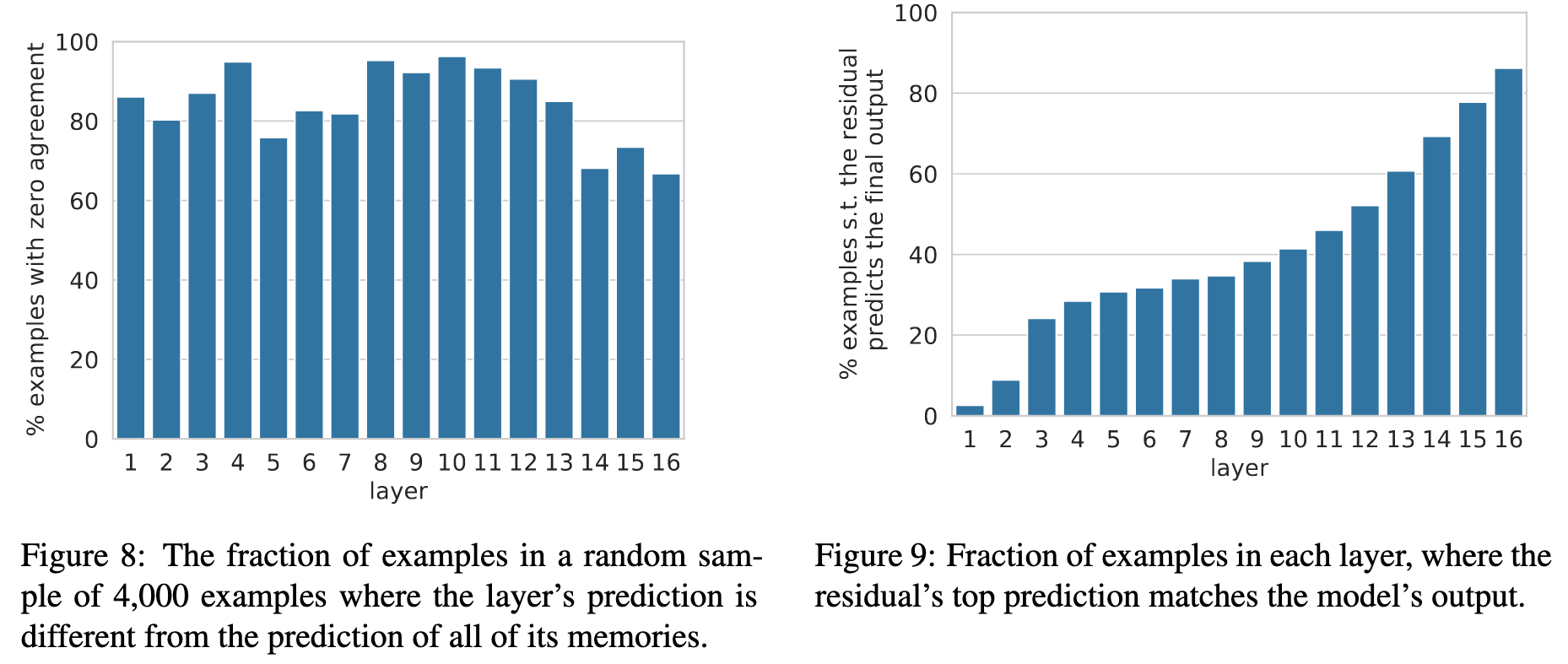
Important | View in local Zotero: page 7
“a multi-layer model uses the residual connection r to sequentially compose predictions to produce the model’s final output”
Important | View in local Zotero: page 7
“the model uses the sequential composition apparatus as a means to refine its prediction from layer to layer, often deciding what the prediction will be at one of the lower layers.”