Cite
Bereska, Leonard, and Efstratios Gavves. Mechanistic Interpretability for AI Safety — A Review. 1, arXiv:2404.14082, arXiv, 22 Apr. 2024. arXiv.org, https://doi.org/10.48550/arXiv.2404.14082.
Metadata
Title: Mechanistic Interpretability for AI Safety — A Review Authors: Leonard Bereska, Efstratios Gavves Cite key: bereska2024
Links
Abstract
Understanding AI systems’ inner workings is critical for ensuring value alignment and safety. This review explores mechanistic interpretability: reverse-engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding. We establish foundational concepts such as features encoding knowledge within neural activations and hypotheses about their representation and computation. We survey methodologies for causally dissecting model behaviors and assess the relevance of mechanistic interpretability to AI safety. We investigate challenges surrounding scalability, automation, and comprehensive interpretation. We advocate for clarifying concepts, setting standards, and scaling techniques to handle complex models and behaviors and expand to domains such as vision and reinforcement learning. Mechanistic interpretability could help prevent catastrophic outcomes as AI systems become more powerful and inscrutable.
Notes
From Obsidian
(As notes and annotations from Zotero are one-way synced, this section include a link to another note within Obsidian to host further notes)
Mechanistic-Interpretability-for-AI-Safety----A-Review
From Zotero
(one-way sync from Zotero)
Annotations
Highlighting colour codes
Link to original
- Note: highlights for quicker reading or comments stemmed from reading the paper but might not be too related to the paper
- External Insight: Insights from other works but was mentioned in the paper
- Question/Critic: questions or comments on the content of paper
- Claim: what the paper claims to have found/achieved
- Finding: new knowledge presented by the paper
- Important: anything interesting enough (findings, insights, ideas, etc.) that’s worth remembering
From Zotero
(one-way sync from Zotero) Imported: 2024-12-04
Note | View in local Zotero: page 1
“mechanistic interpretability: reverse-engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding.”
Important | View in local Zotero: page 1
“The interpretability landscape is undergoing a paradigm shift akin to the evolution from behaviorism to cognitive neuroscience in psychology.”
Note | View in local Zotero: page 1
“Historically, lacking tools for introspection, psychology treated the mind as a black box, focusing solely on observable behaviors. Similarly, interpretability has predominantly relied on black-box techniques, analyzing models based on input-output relationships or using attribution methods that, while probing deeper, still neglect the model’s internal architecture.”
Important | View in local Zotero: page 2
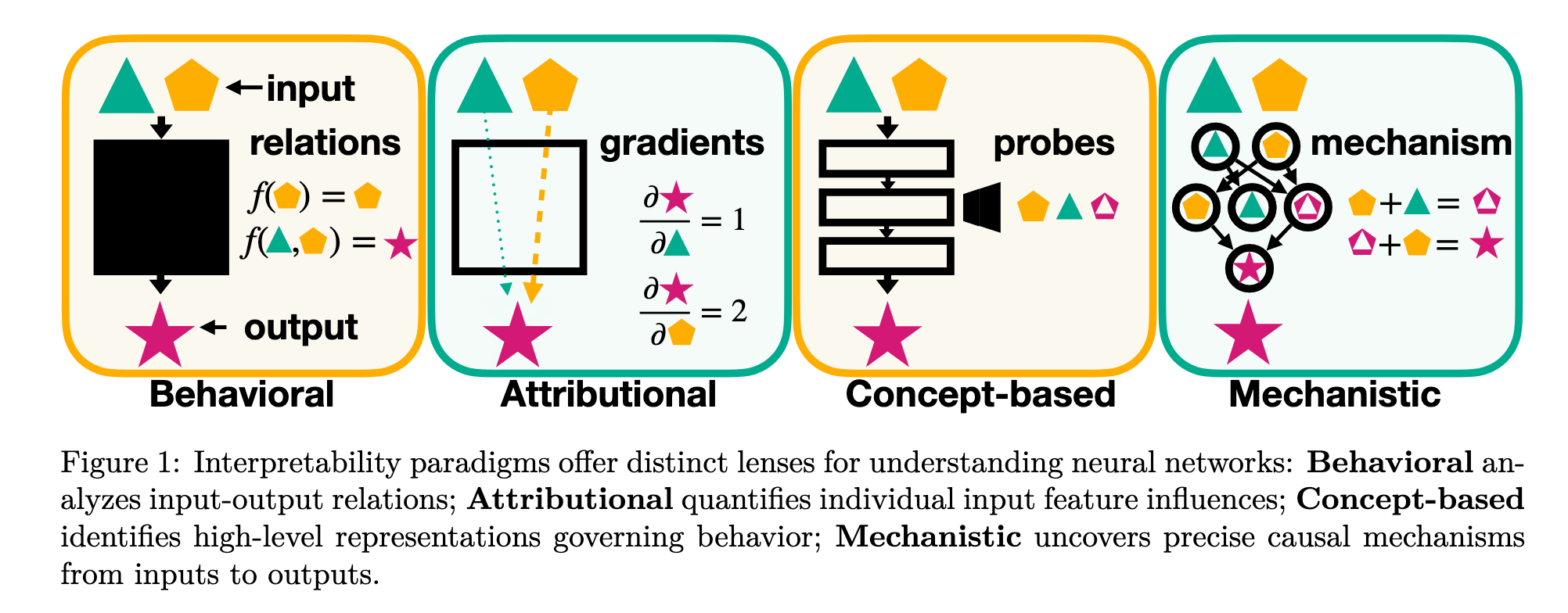
External Insight | View in local Zotero: page 3
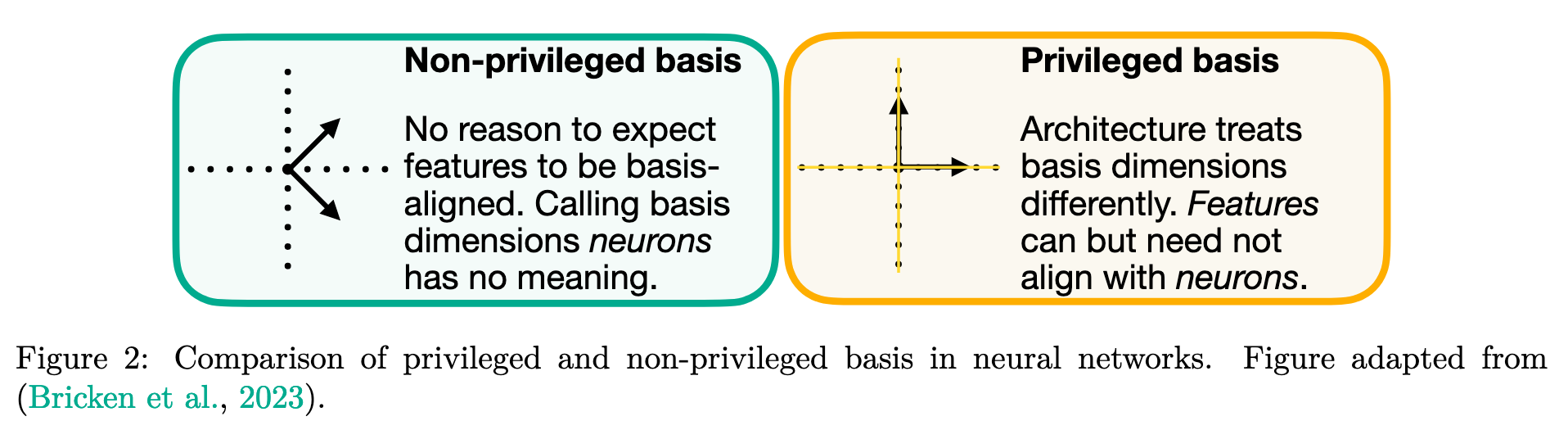
External Insight | View in local Zotero: page 3
“A non-human-centric perspective defines features as independent yet repeatable units that a neural network representation can decompose into (Olah, 2022).”
Note | View in local Zotero: page 4
“Hypothesis: Superposition Neural networks represent more features than they have neurons by encoding features in overlapping combinations of neurons.”
Important | View in local Zotero: page 4
“Non-orthogonality means that features interfere with one another.”
Note | View in local Zotero: page 5
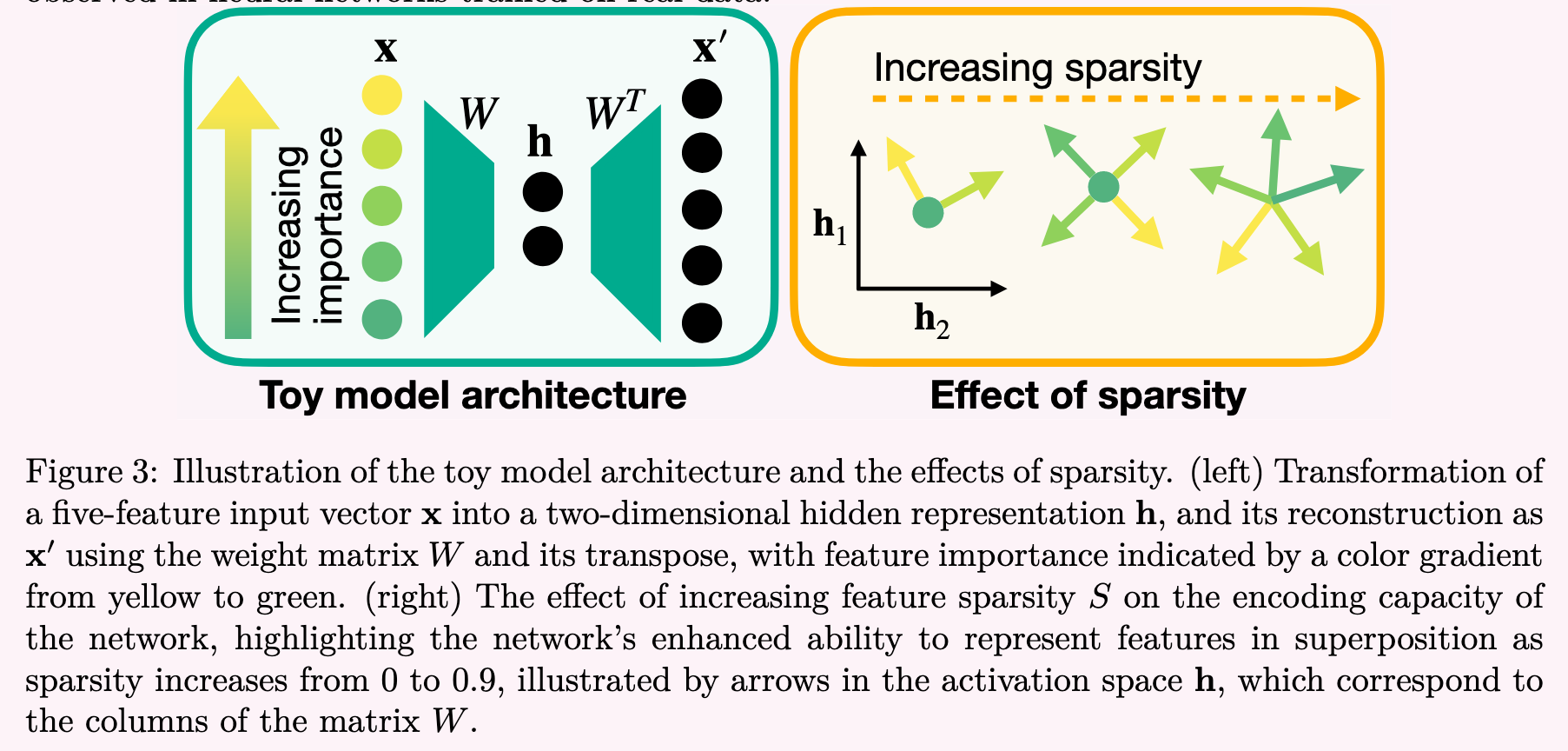
Note | View in local Zotero: page 6
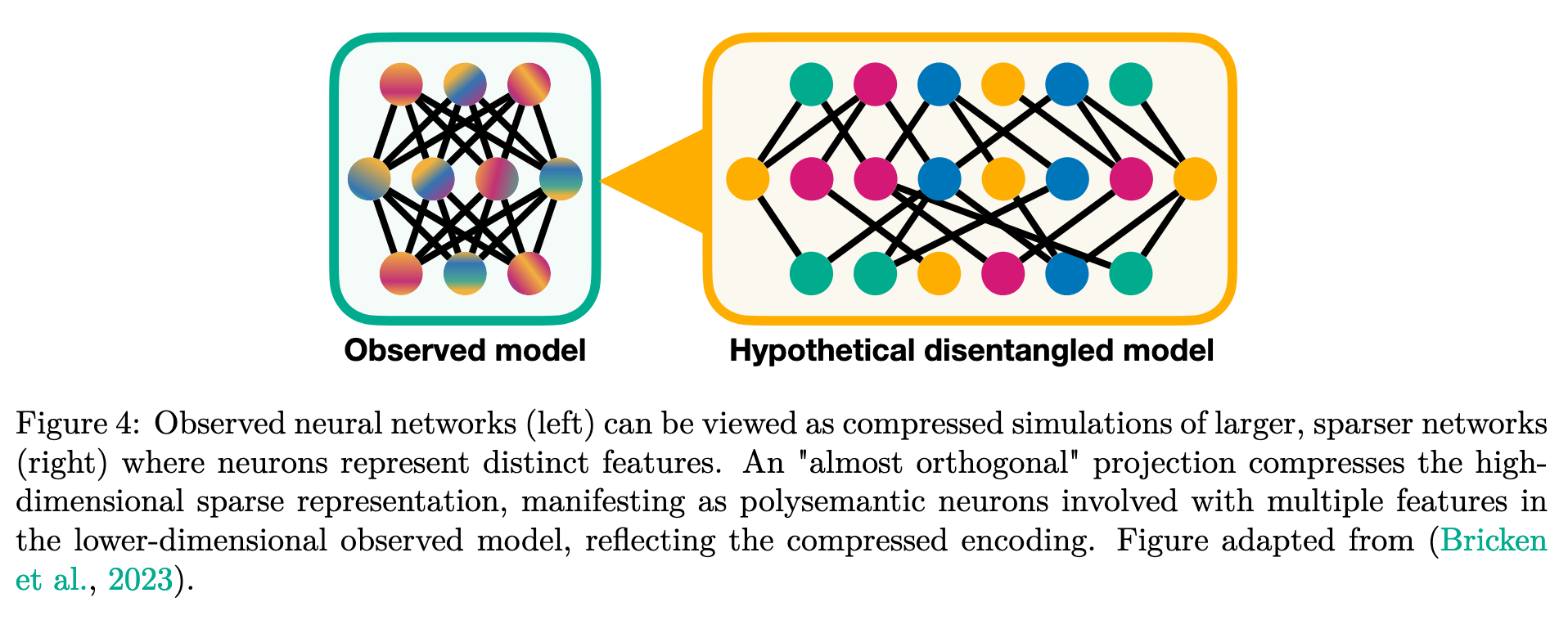
Note | View in local Zotero: page 8
“Definition: Circuit Circuits are sub-graphs of the network, consisting of features and the weights connecting them.”