Why
- fine-tuning is often modifying the weights of the whole model
- but not all of us have fancy GPUs that can fit all the weights
- sometimes you want different copies of the models fine-tuned for different purposes
What
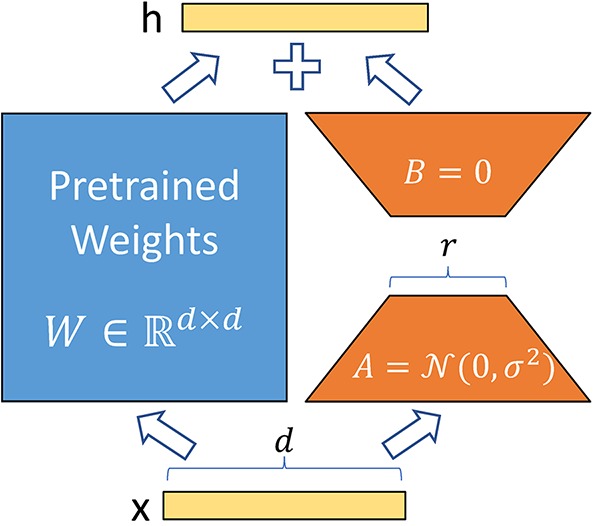
- the left is the pre-trained weights
- learn the things on the right
- the delta that needed to modify the pre-trained weight
- in LoRA, the delta doesn’t need to be as big as the pre-trained weights
- factorize them into 2 low-rank matrices that when multiply will approximate the big one
Hence
- tends to work really well in practice, thus it is popular
- dramatically reduces memory usage
- don’t need to store much during forward and backward passes, just the LoRA weights and the main model
- don’t need to do backward pass on the main model
- no optimizer states
- no gradients
- no need to store the activations
- doesn’t help speed very much
- still have to do forward pass through the whole network
- plus forward and backward for the LoRA weights
- good for low memory GPU