- sparse fine-tuning (SFT) for LLMs
- adding a sparse vector ϕ to the model weight θ
- LoRA (top) vs Sparse Fine-Tuning (bottom)
- address the memory footprint problem
- SFTs usually consider all LLM parameters
- by only keep a fixed-size vector of SFT parameters of model weight indices, then iteratively perform 3 operations:
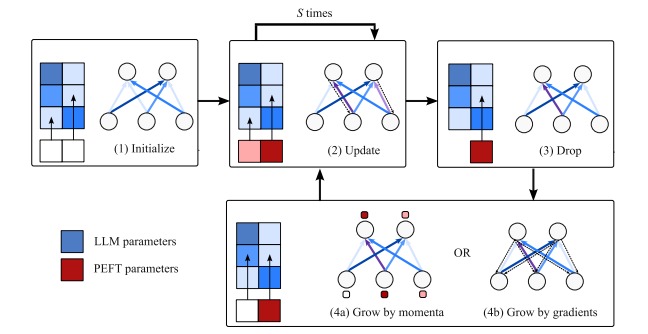
- update: update the PEFT deltas corresponds to the active indices
- drop: prune indices based on the change of magnitude of their deltas
- grow:
- choosing new indices to be active, base on 1 of 2 criteria
- accumulated gradients of a few candidate parameters
- approximate momenta estimated using SM3 optimizer
- gradient estimation are estimated for some training steps not just 1
- this is called the “gradient estimation phase”
- only maintain estimation for k “growth candidates”
- selected as top-k gradient magnitude during the first batch of the gradient estimation phase
- this might be biased towards the first training step (and the training examples used in that step) idea
- instead of that, dynamically update the candidates by getting top-k at each step
- get the top-k out of the existing candidates and top-k from the current step (up to 2k total)
- based on their running average of gradient magnitude
- with higher priority for the more “senior” candidates