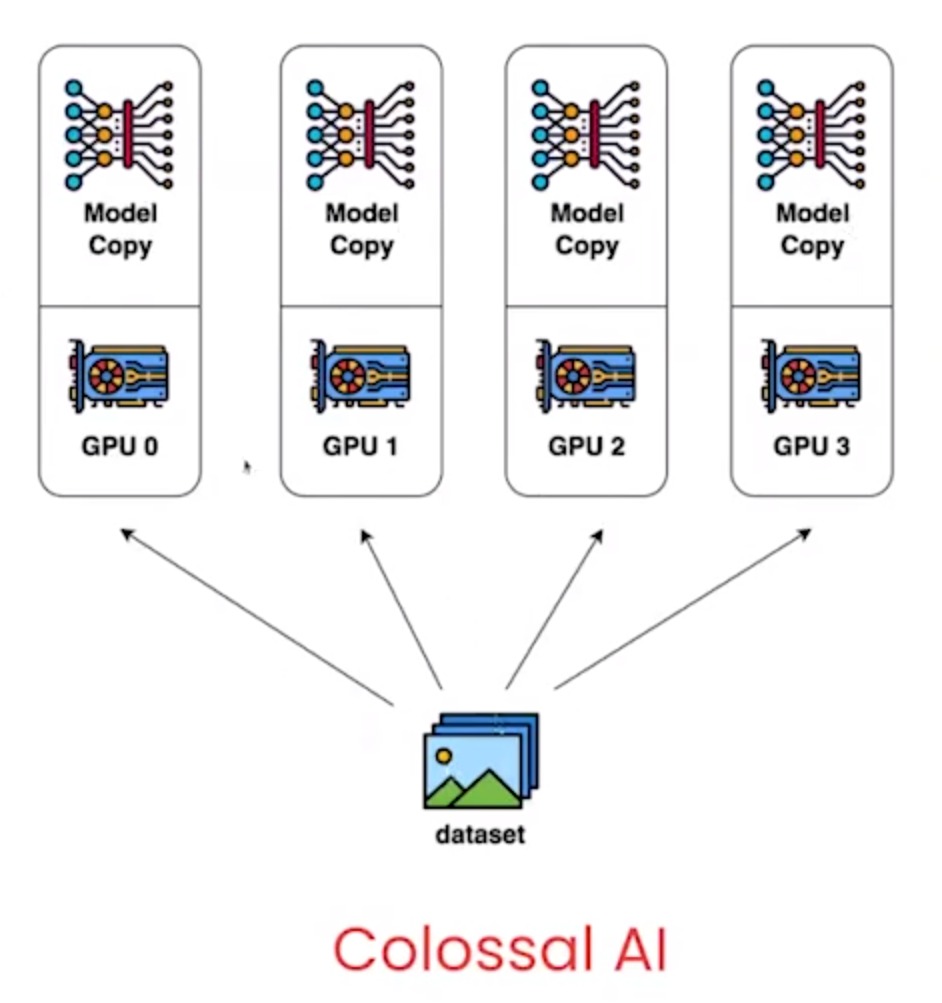
distributed What multiple GPUs a separate copy of the model on each GPU feed different data on each GPU average the gradients when done Hence speed up training