mechanistic-interpretability research
Remove KV entries with least important features.
Ideas:
- As see in Refusal behaviour can be controlled by turning a knob, the strength of the refusal direction in the last decoder block changes suddenly. It could be that in this layer, the model prunes off unnecessary features, making the important ones stronger. So we can try to extract directions that the last decoder layer overlaps the most with other layers.
- Another one is to apply the idea in eigen values and Page Rank
- compute eigen vectors to analyze the matrices in transformers (the A, QK, OV matrices in self attention and the matrices in the MLP layer ? At each of these transformations, there will be a direction that won’t be scaled, what does this direction represent ? question
- the attention matrix A is already a Markov Matrix so it’s suitable
- other matrices could also be considered if every row or every column sum to 1 (or approximately).
- it’s might be true as we discussed from Angular Steering that all Attn and MLP layers take as inputs fixed-norm vectors due to the use of LayerNorm.
(visualization of self attention for reference while thinking)
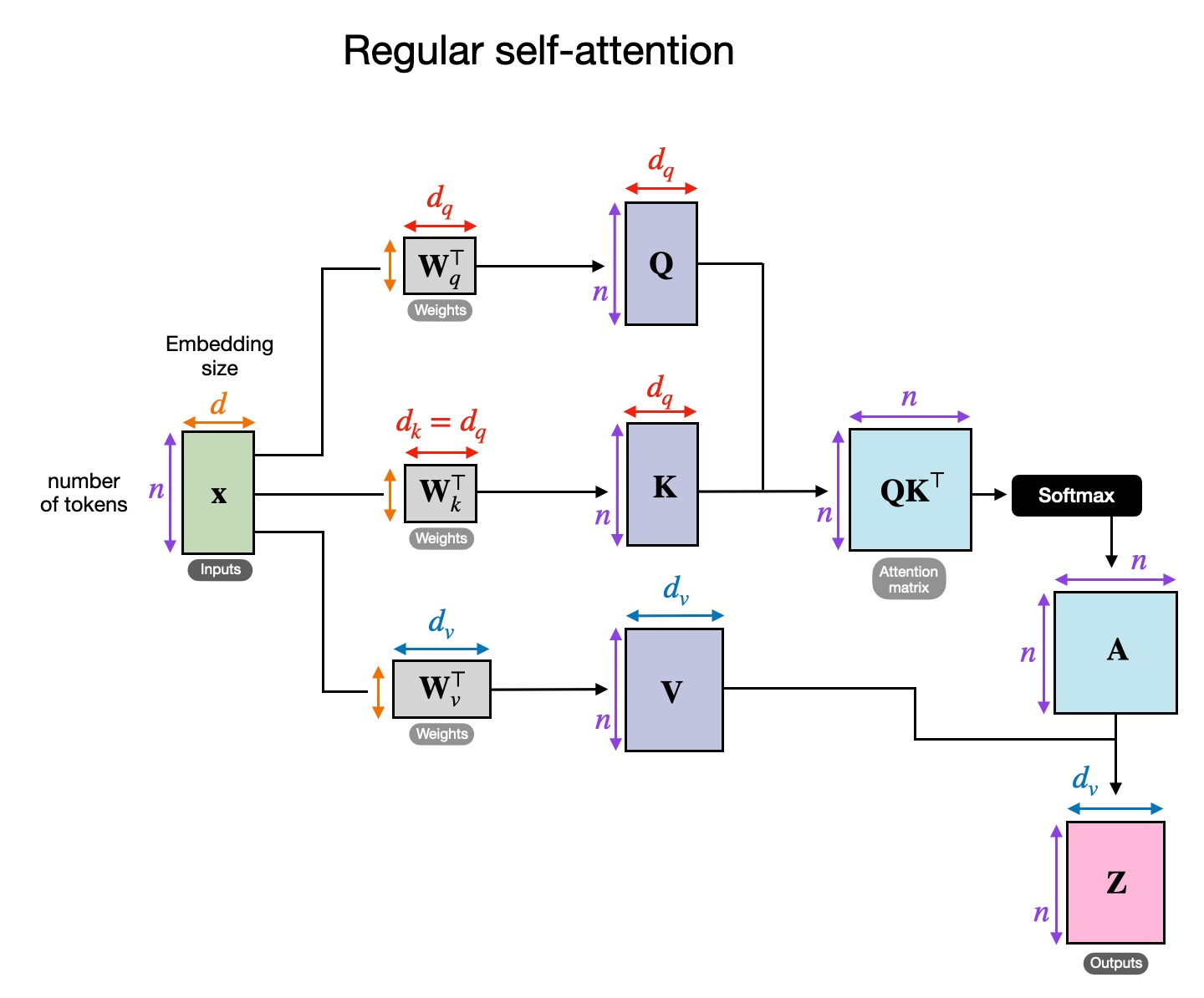
- it’s might be true as we discussed from Angular Steering that all Attn and MLP layers take as inputs fixed-norm vectors due to the use of LayerNorm.
(visualization of self attention for reference while thinking)