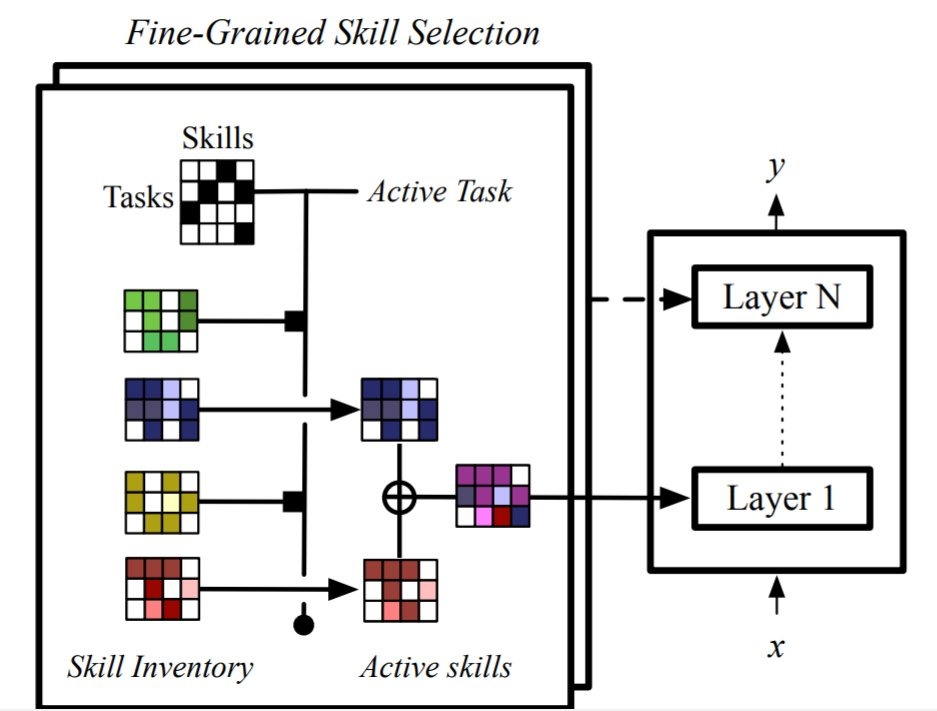
- learn a task-skill binary matrix to select the skills based on the task
- binary matrix enforces the skills to be discrete
- but it cannot be learned via gradient descent
- so they implemented is as a collection of continuously relaxed Bernoulli distributions through a Gumbel-sigmoid (what’s that ?)
- each task is associated with a dataset and a loss function
- are the tasks fixed ?
- if so how to generalize to new tasks ?
- through few-shot learning
- by adding a new row to the task-skill matrix ?
- each skill is a spare parameter (matrix ?)
- this represents the long-term memory for task-level knowledge
- the short-term memory for input-level knowledge is represented by how the modules may compete to attend different parts of a structured input
- all skill parameters are combined and used as layer parameter
- disentangle representation for skills and tasks