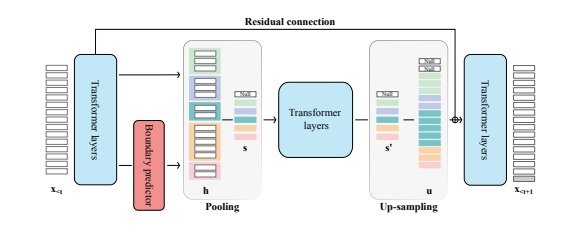
- jointly learn dynamic pooling (token segmentation) and language modelling
- but the number of boundaries is also dynamic, so how does the transformer layers work with it ?
- upsampling is by duplication
- Can we apply the ideas of U-Net or deconvolution here ? idea
- learn dynamic pooling by predict segment boundaries in the sequence dynamically
- normally pooling used fixed size, which is sub-optimal for language
- help preserve linguistic primitives during pooling
- try to make the model perform
- hierarchical computation
- conditional computation by allocating resources to sub-sequences in proportion to the model uncertainty
- learn the neural boundary predictor supervised by
- unigram tokenizer
- end-to-end through stochastic re-parameterisation
- spikes in the conditional entropy of the predictive distribution
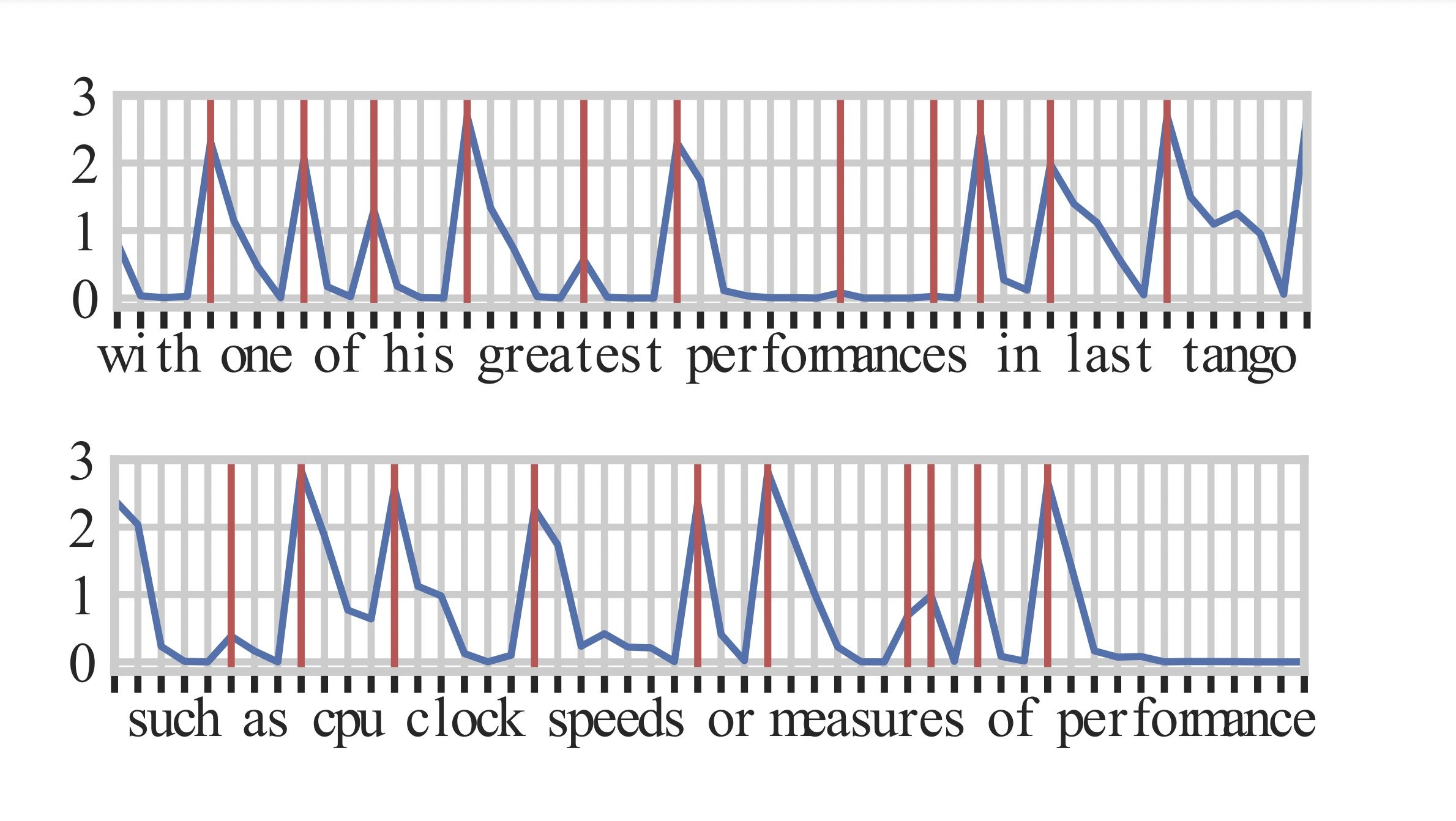
- ensure that the computation is adaptive to the level of uncertainty
- this and Gumbel-sigmoid are inferior to alternatives for dynamic pooling
- why ? this is such a cool idea
- natural data boundaries such as white spaces