In Transformer Feed-Forward Layers Are Key-Value Memories, the interaction between the input and each column of the first parameter matrix is viewed as a conditional distribution of given :
Link to original
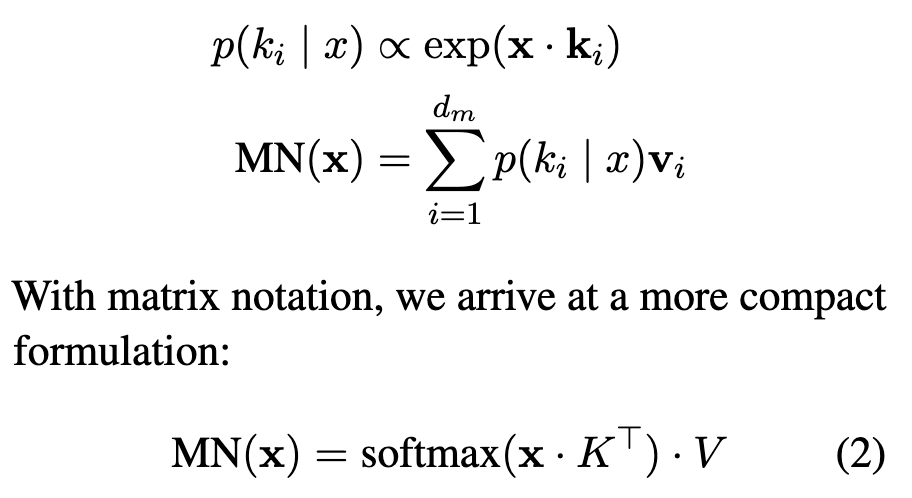
What if we employ the idea of VAE and make parameterizing as Gaussian, something like:
which is a Gaussian with mean give by and a fixed std.
The intuition is, given an input that produces , if is distributed near then it is more likely to be related to . This will force the model to learn such that it’s distributed near .
But perhaps the MLP already has this property ? As is bigger when and are more co-linear, the “almost co-linear” region surrounding can be seen as a distribution parameterized (partly or entirely) by .