training
-
Pipeline parallelism
What
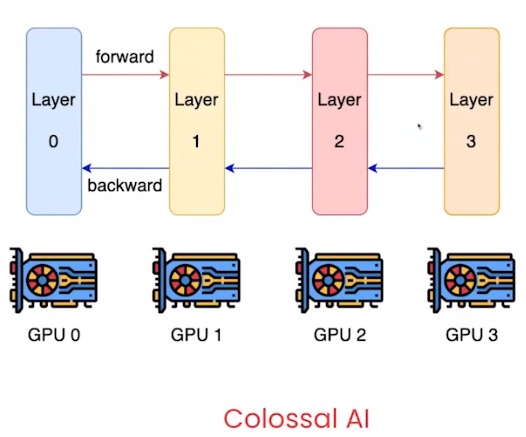
- have each layer of the network on a different GPU
- constantly sending data forward and backward through the GPUs
Link to original
-
Data parallelism
What
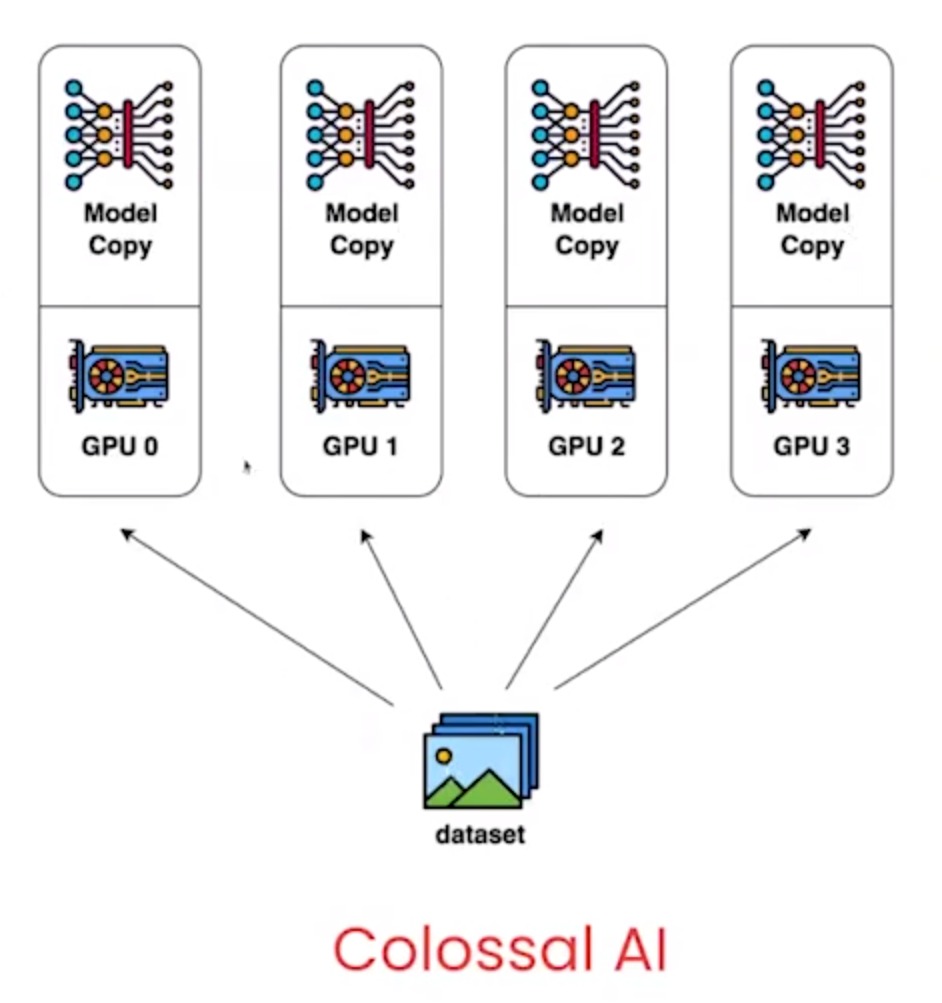
- multiple GPUs
- a separate copy of the model on each GPU
- feed different data on each GPU
- average the gradients when done
Link to original
-
Tensor parallelism
What
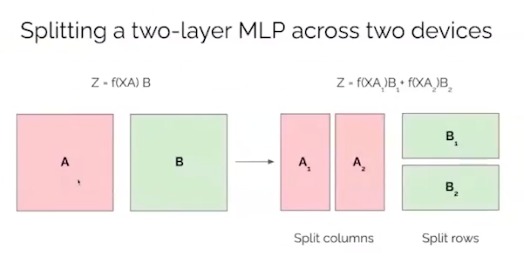
- Matrix multiplication factorization
- split matrix to create smaller matrices to do multiplication.
- Z=f(XA)B−>Z=f(XA1)B1+f(XA2)B2
- Do A1B1 on one GPU and A2B2 on another GPU, or both on the same GPU but separately
Link to original