hypothesis
activation space is Euclidean
behaviours are represented by directions in the activation space
- *Refusal in LLMs is mediated by a single direction — LessWrong
- different directions have varying effects on refusal
activation spaces of layers share similar geometric properties
different directions represents different behaviour or varying effects of one behaviour
implications
linear directions as behaviour toggles
- if some behaviours of the model can be represented as a single direction across layers, then that direction can be used as a key to lock/unlock certain regions in the activation space (can be see as knowledge) idea
- removing the direction = lock the access to some knowledge
- adding back the direction = unlock knowledge
- can be used to modularized the behaviours of the model modular-learning idea
- model weights can be distributed with only some “knowledge”/behaviours disabled, and can be enabled on demand later
- we could force the model to “organize” some “knowledge” or behaviours in a specific direction, which means those “knowledge” or behaviours will be hidden away if said direction is not present in the activations
on model merging
According to What Matters for Model Merging at Scale?, these findings were presented:
- Instruction-tuned models facilitate model merging.
- this would make sense if instruction fine-tuning introduces new behaviour directions into the model weights hypothesis
- this might be related to
the use of chat template seems to be important
- chat template makes it easier to choose the token position to extract the direction
- the few last tokens which is the suffix of the template after the main content was used
- with left padding, these tokens aligned across samples making it suitable for comparison
- with template vs no template on Qwen-1-8B-chat
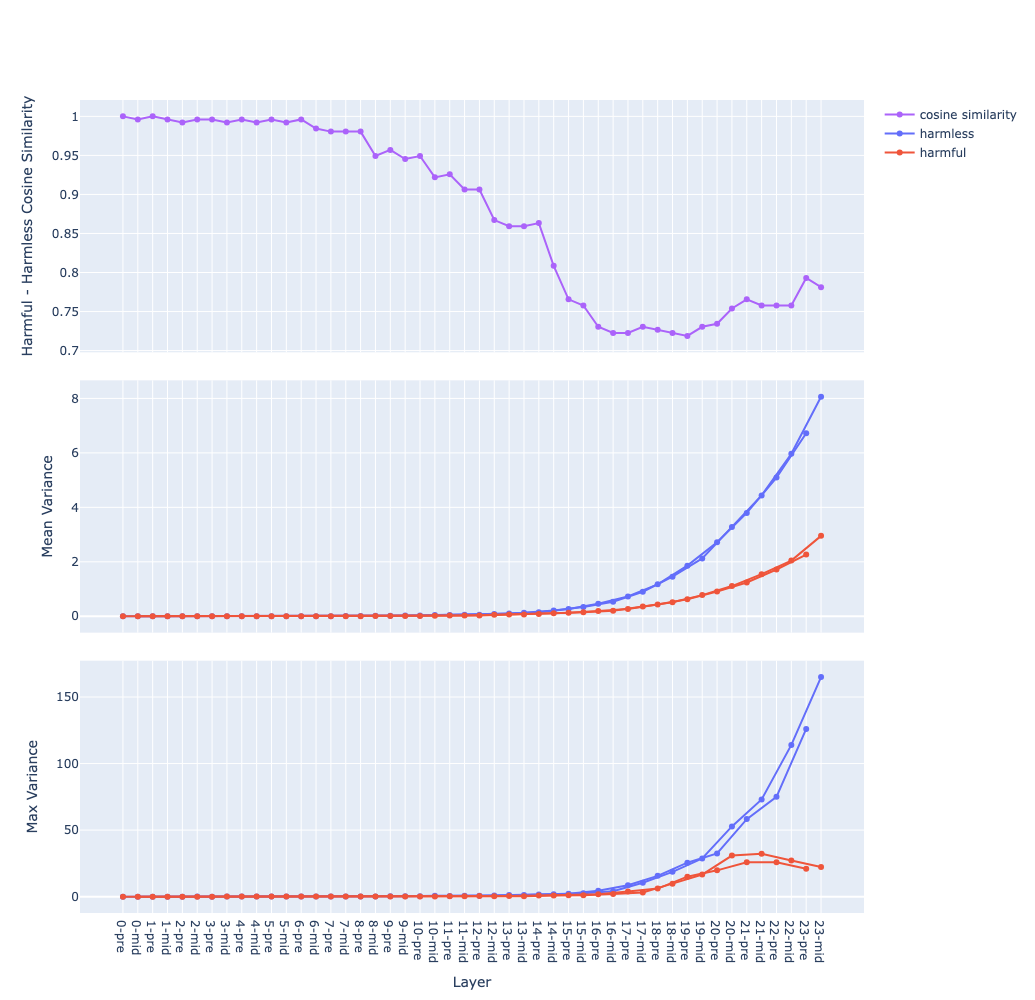
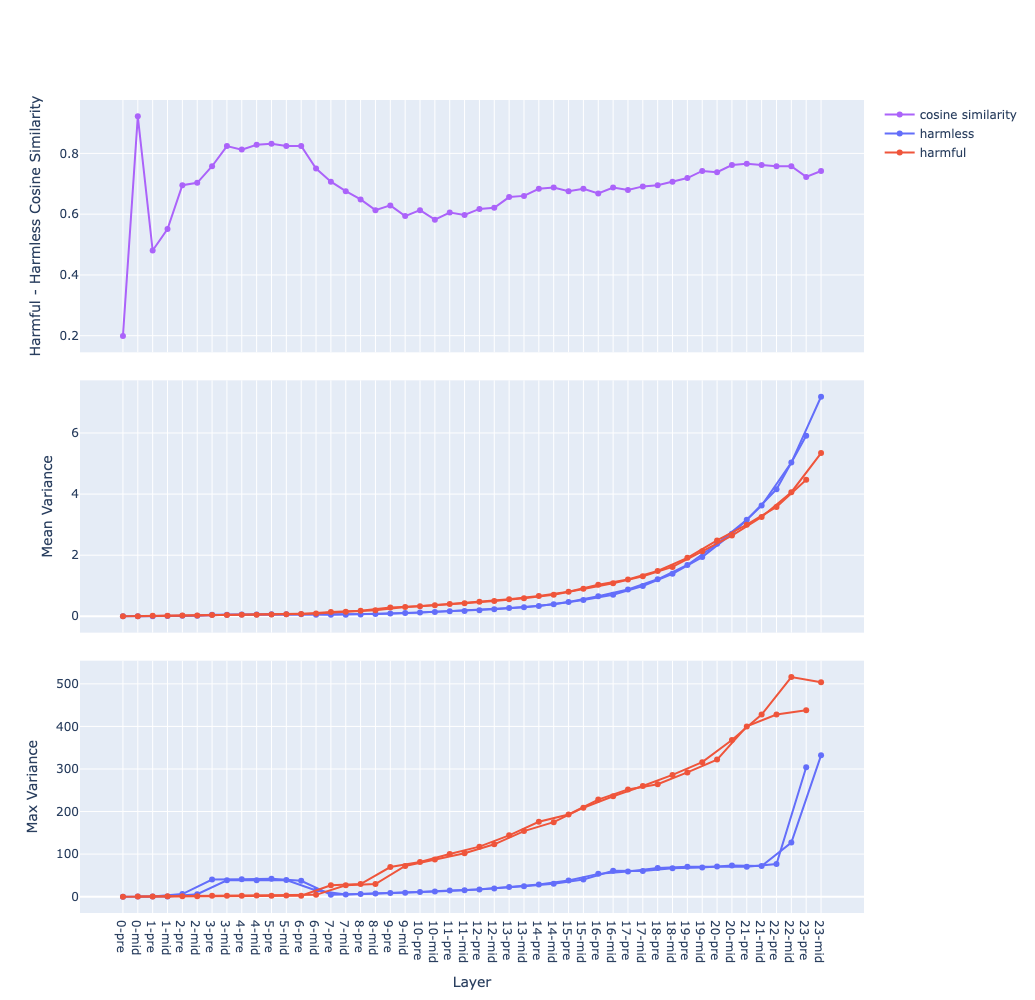
- this might suggest that instruction fine-tuning introduces behaviour vectors to the model hypothesis
- but by just adding a newline character at the end, it will have a not as good but similar effect to using a template
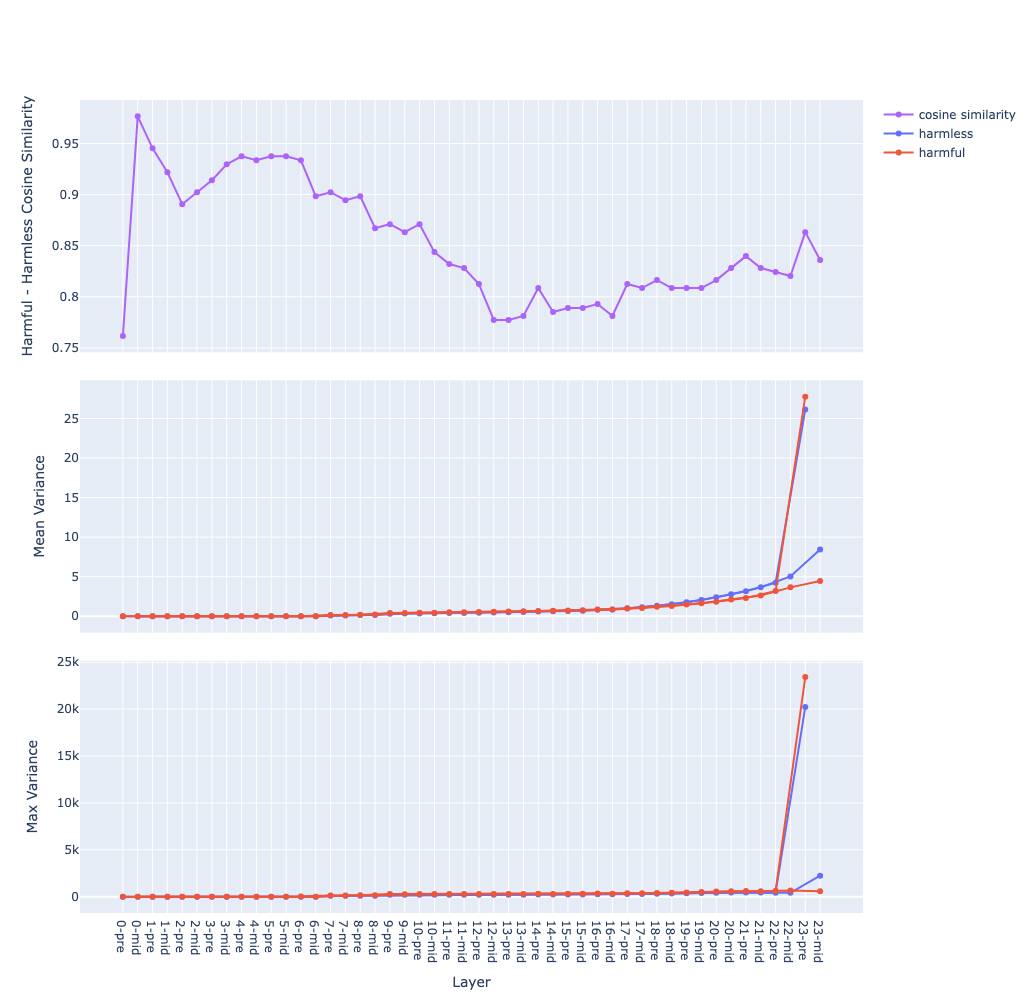
- chat template makes it easier to choose the token position to extract the direction
- Model merging becomes easier with bigger models
- This can be explained that with bigger models, the activations have higher dimension, thus the basis from the matrix transformations at each layer are more separated (have lower cosine similarity) hypothesis
- Thus when merged, these directions are combined with less cancelling out effect
- Merged models at scale generalize better
- Same reasoning as above, with higher dimension, the basis are more likely to be orthogonal hypothesis
- thus the model is able to represent more fine-grained “skill” vectors
- the combination of some of these “skill” vectors might be beneficial for generalizing to new tasks
- Bigger model sizes can merge more expert
- Also using the same reasoning, higher dimensional space can fit more orthogonal “skill” vectors