Control Vectors vs Prompting
- Prompting steer the generation by adding more distracting tokens to “overwhelms” the activation space.
- Control vectors in the other hand alter the activation space directly, thus potentially be more effective and harder to be undone.
on controlling refusal behaviour1
single refusal direction are applicable across layers
- ablation can be applied anywhere and need not to be applied on the layer where it was extracted to have an effect observation
- this suggests that activations from all layers are on the same space hypothesis
- which in turns means the input and output of a transformer layer are on the same space
- this could be due to
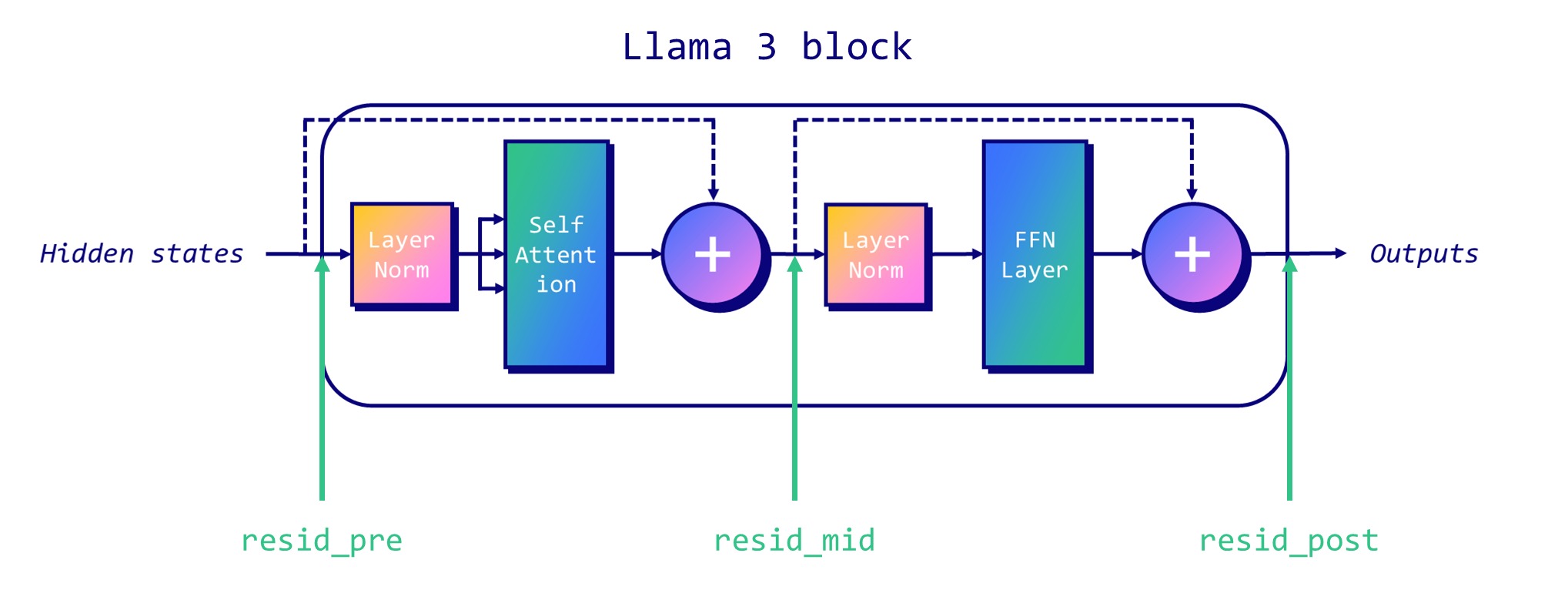
For a transformer layer:
Link to original - if a single direction can be applied to all layers, what does it tell us about the basis of each layer ? question
- this suggests that activations from all layers are on the same space hypothesis
- ablation works when applied on a subset of layers, even if the subset does not include the layer where the intervention direction was extracted from observation
- It seems to work when applying on layers with low cosine similarity between 2 the avg vectors of 2 contrastive datasets observation
- the intervention layers don’t need to be consecutive observation
- for Qwen 1 8B, tried layers in
range(8, num_layers, 2)and it still works
activations space can be analyzed using Euclidean metrics
- using cosine similarity and mean/max variance of activations seems to be great metrics to choose the intervention layers observation
- an ideal layer for extraction would have, in order of importance idea
- low mean of variance for each sample set, suggesting that the sample are densely clustered
- low max of variance for each sample set, also suggesting dense clusters and also no outlier dimension
- low cosine similarity between mean activation vectors, suggesting the clusters are far apart
- this suggests that the space of the activations is Euclidean hypothesis
- this could also mean that, for classification task, the ideal layer described above would work best
- an ideal layer for extraction would have, in order of importance idea
- how to check if the activation space is Euclidean given a set of vectors in that space ? question
- by calculating the Riemann Curvature Tensor using triangles ?
transformer layers expand and “untangle” the activation space
Steps to compute these graphs:
-
data sets: 2 contrastive data sets, in this case are
harmfulandharmless -
feed each data sets through the model and capture activations
- at each residual stream2
- at each layer
- at the last token
→ we get 2 matrices
P(positive) andN(negative) of sizesamples x layers x features
-
the top graph:
- compute the mean vector for each data sets:
X_mean = X.mean(dim=<sample>)→ we get 2 matricesP_meanandN_meanof sizelayers x features - compute the cosine similarity between the 2 vectors at each layer (e.g.
P_mean[l]andN_mean[l]), we get a vector of size1 x layerssimilarity_score = cosine_similarity(P_mean, N_mean, dim=<hidden>)
- compute the mean vector for each data sets:
-
the middle graph:
- compute the variance vector for each data sets:
X_var = X.var(dim=<sample>)→ we get 2 matricesP_varandN_varof sizelayers x features - then compute the mean along the feature dimension, we get 2 vectors of size
1 x layers:P_var_mean = P_var.mean(dim=<hidden>)N_var_mean = N_var.mean(dim=-<hidden>) - 2 curves of the same colour are for 2 residual streams, in this case are
preandmid
- compute the variance vector for each data sets:
-
the bottom graph: same as the middle one but for max instead of mean
Observations, questions and hypotheses
-
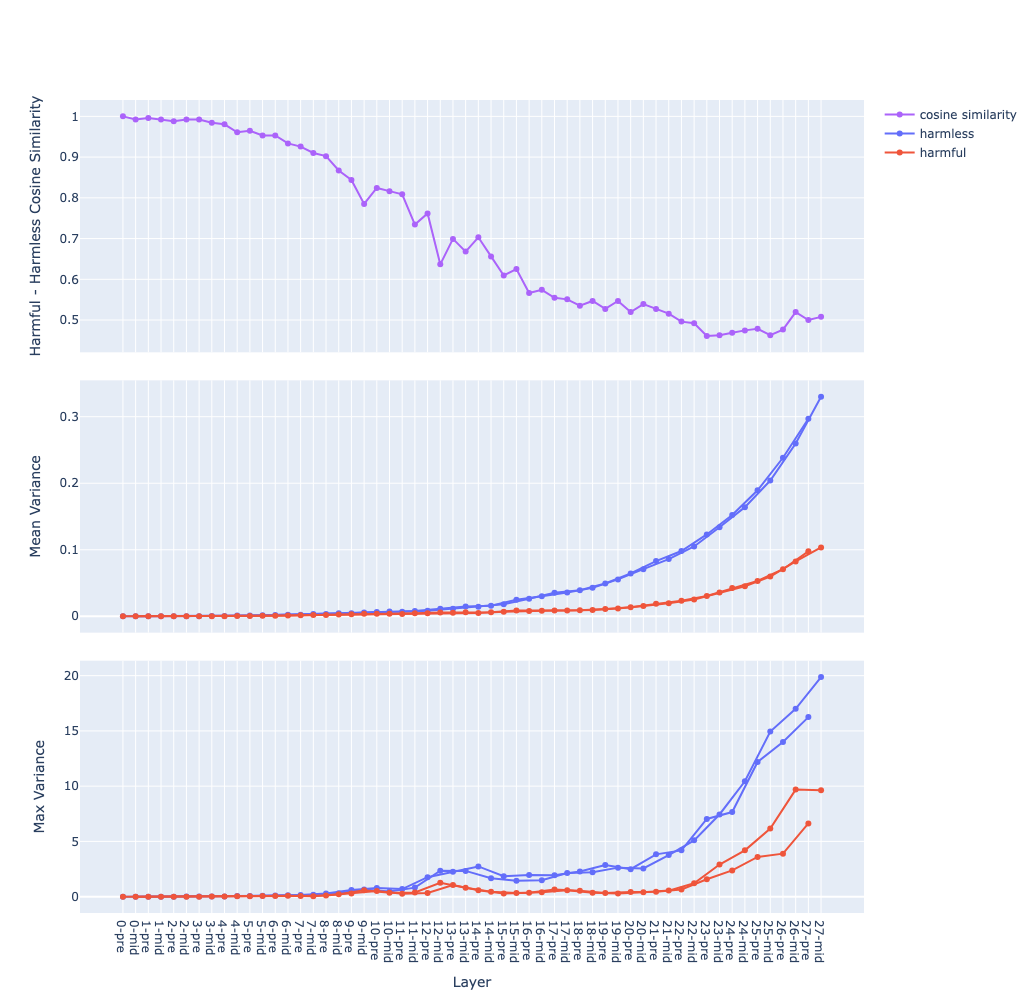
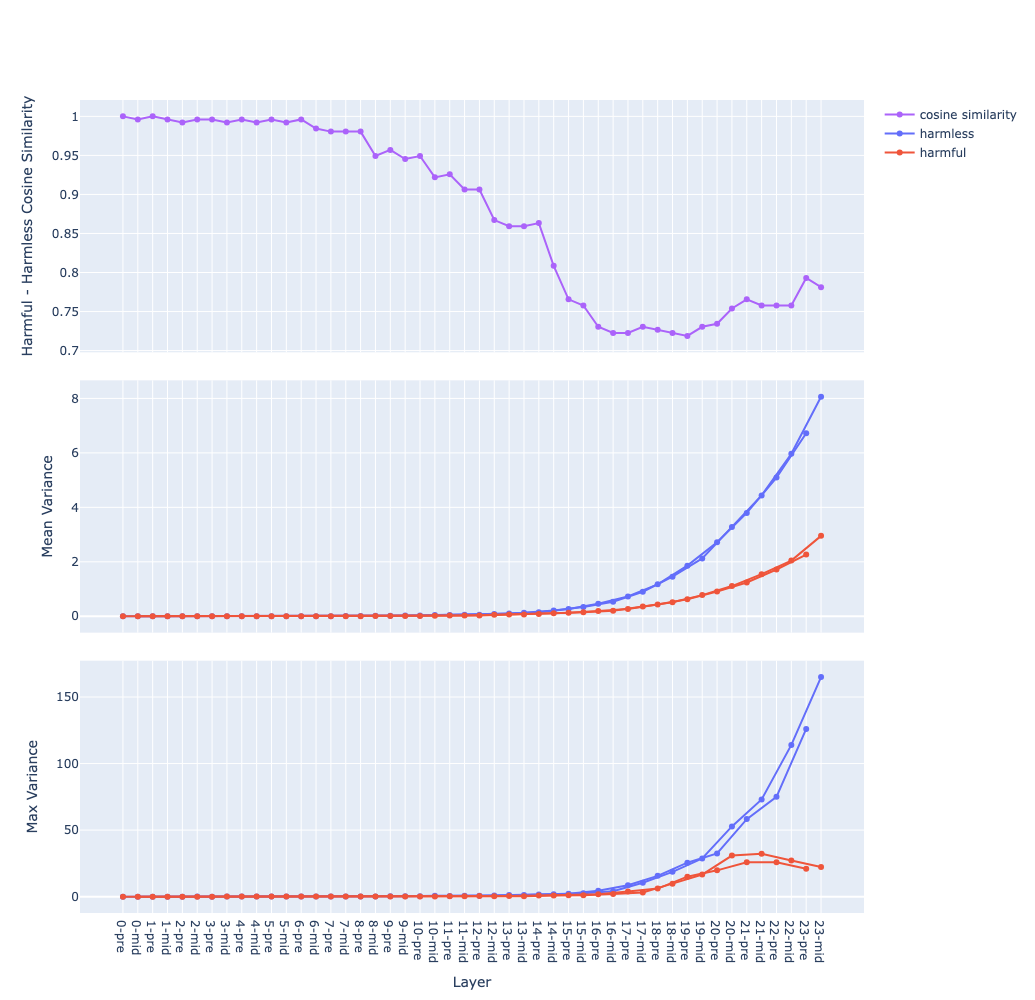
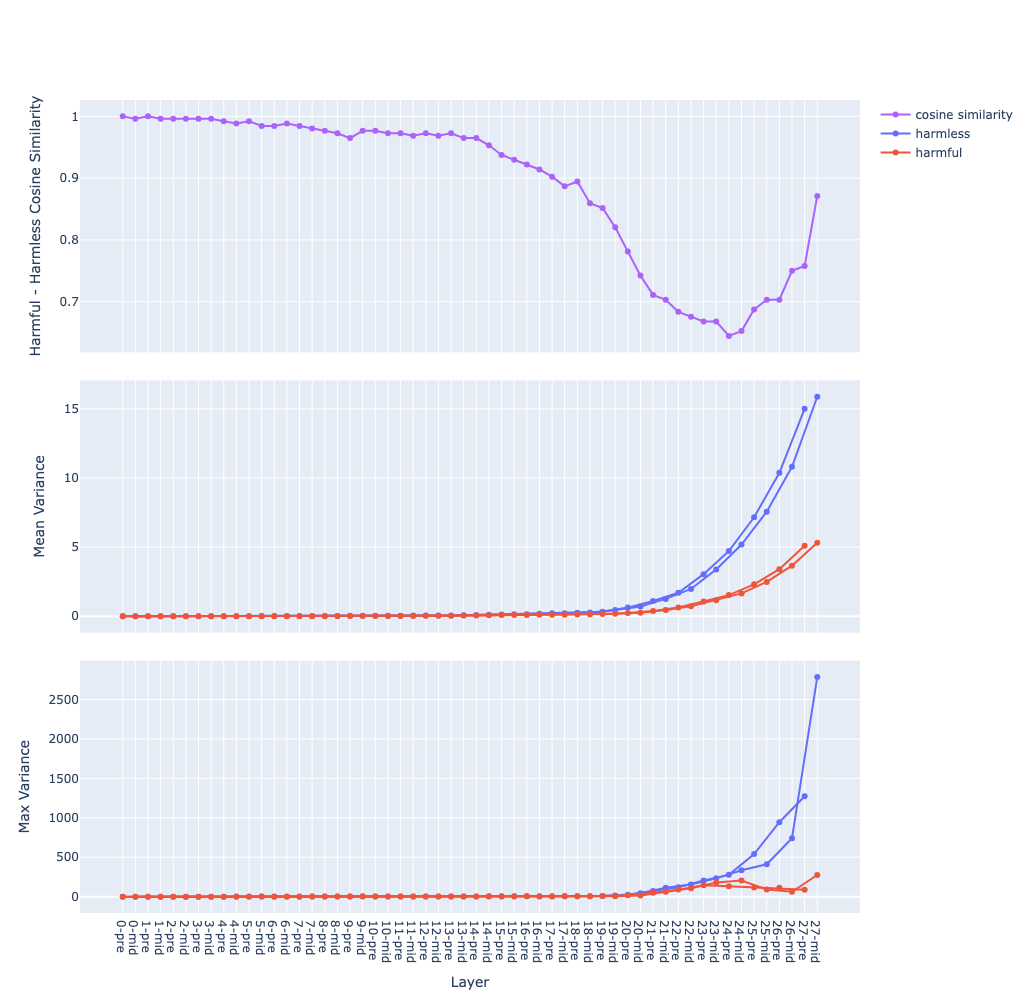
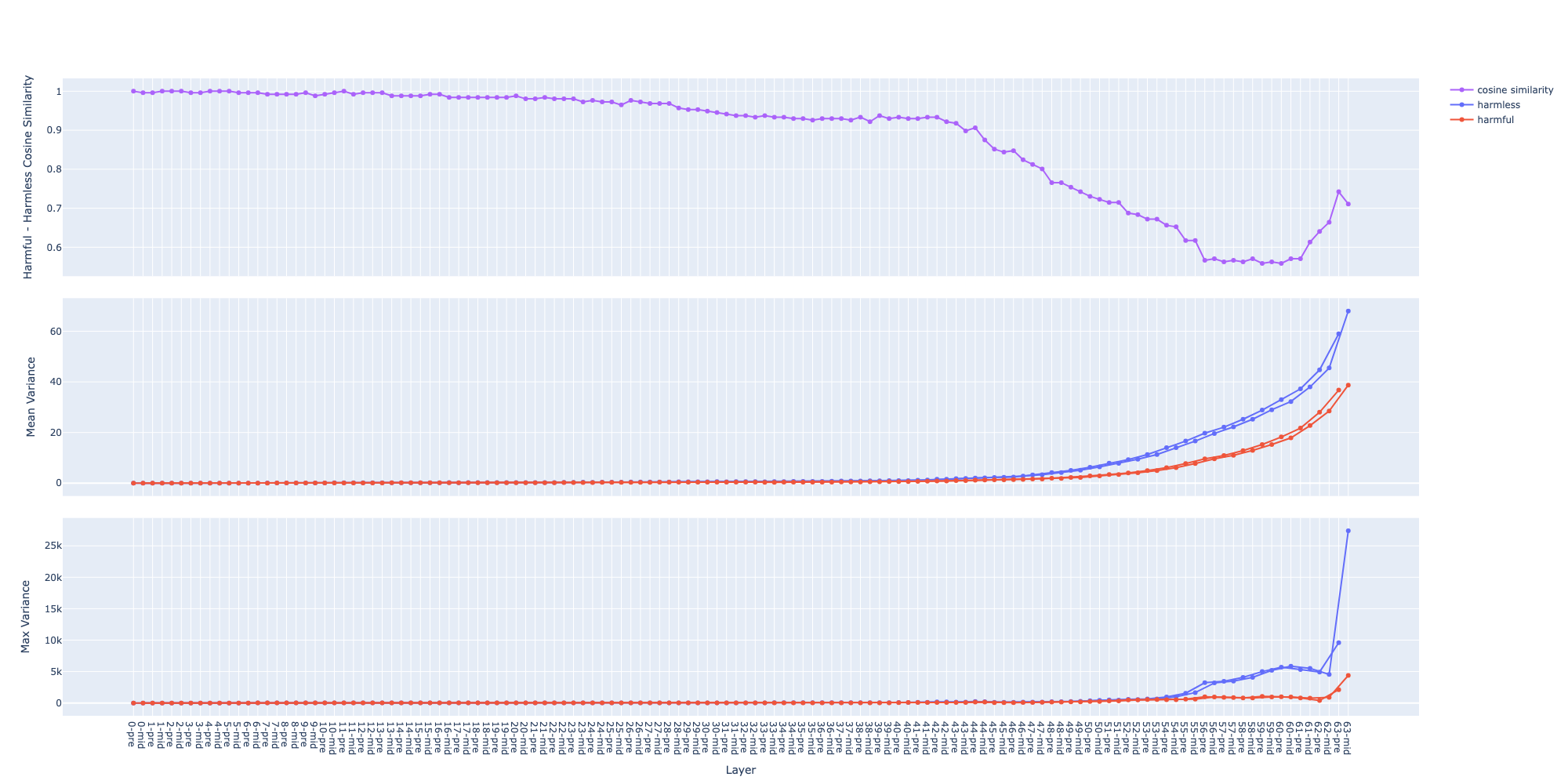
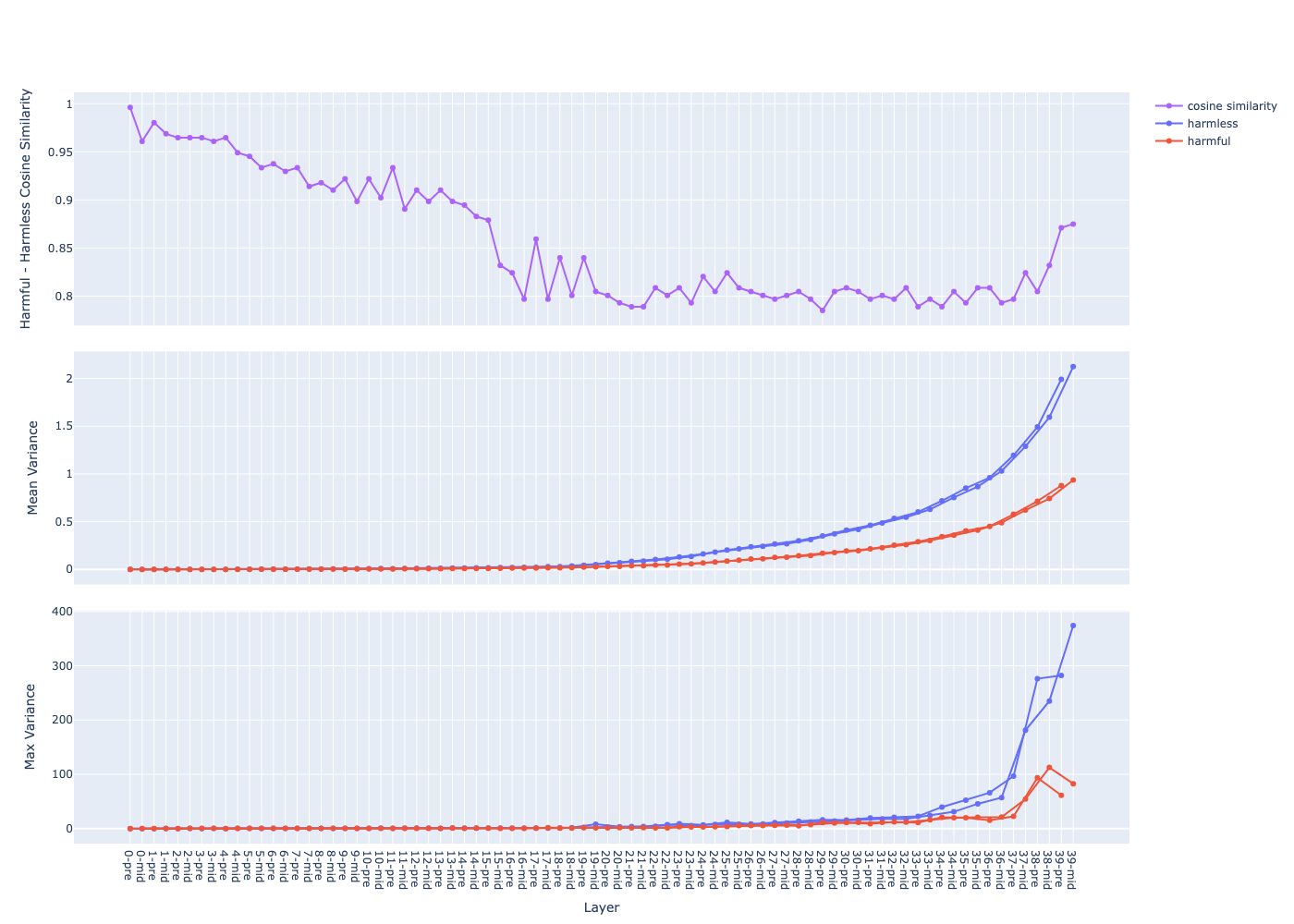
The mean of variance (the middle graph) grows in a near-exponential trajectory from the first to last layer observation why ? question
- The growth of
pre(before attention) andmid(after attention) streams are separated observation why ? question - Hypothesis: hypothesis
- the model start with an initial state (the activation of the 1st layer) near the origin (due to input vector and the weights are usually between 0 and 1)
- each layer move the current state (the activation) through the activation space in some directions
- the directions are similar between layers, hence the state goes further and further along those directions
- suppose that the step size moved by each layer is within a similar range (due to layer norm), then total distance travelled (the norm of the activation vector) grows linearly
- hence the variance (distance squared) grows exponentially
- we can analyze this by checking for shared directions between the weights across layers experiment
- The growth of
-
Transformer layers expand and “untangle” the activation space the deeper we go hypothesis
- different samples would be aligned in different directions, hence they move further away
-
Setting high temperature (e.g. 1.0) reintroduces refusal
- try extracting the direction from activations from multiple generation with high temperature experiment
- This might increase the quality of the extracted feature direction
- try extracting the direction from activations from multiple generation with high temperature experiment
Visualization on several models of different sizes and families
-
Llama 3.2 3B
-
Qwen 1 8B
-
Qwen 2.5 7B
-
Qwen 2.5 32B
-
Mistral-Nemo-Instruct-2407 (12B)
different directions have varying effects on refusal
- some weaker directions (extracted from less ideal layers) can cause the model to refuse but then still answer the harmful request (happened with Qwen1_8B-chat with no chat template) and with Llama-3.2-3B-Instruct
- Qwen models tend to include Chinese response after the English one, could this tell us anything about the data that the models were trained on ? question
- it’s harder to find a good refusal direction for LLama3.2 compared to Qwen1 and Qwen2.5. Many times the model after ablated would refuse the request in a different way (e.g.
As an AI model ...toI can't help you with that request ...)- this might suggest that Llama3.2 was trained/fine-tuned with multiple round of alignment hypothesis
- apply more than 1 time the process of extracting and ablating refusal direction may elevate this. If that works then it means there could be multiple refusal direction representing different behaviours and can be ablated one by one idea
- given a refusal direction, how to vary its effect ? question
the use of chat template seems to be important
- chat template makes it easier to choose the token position to extract the direction
- the few last tokens which is the suffix of the template after the main content was used
- with left padding, these tokens aligned across samples making it suitable for comparison
- with template vs no template on Qwen-1-8B-chat
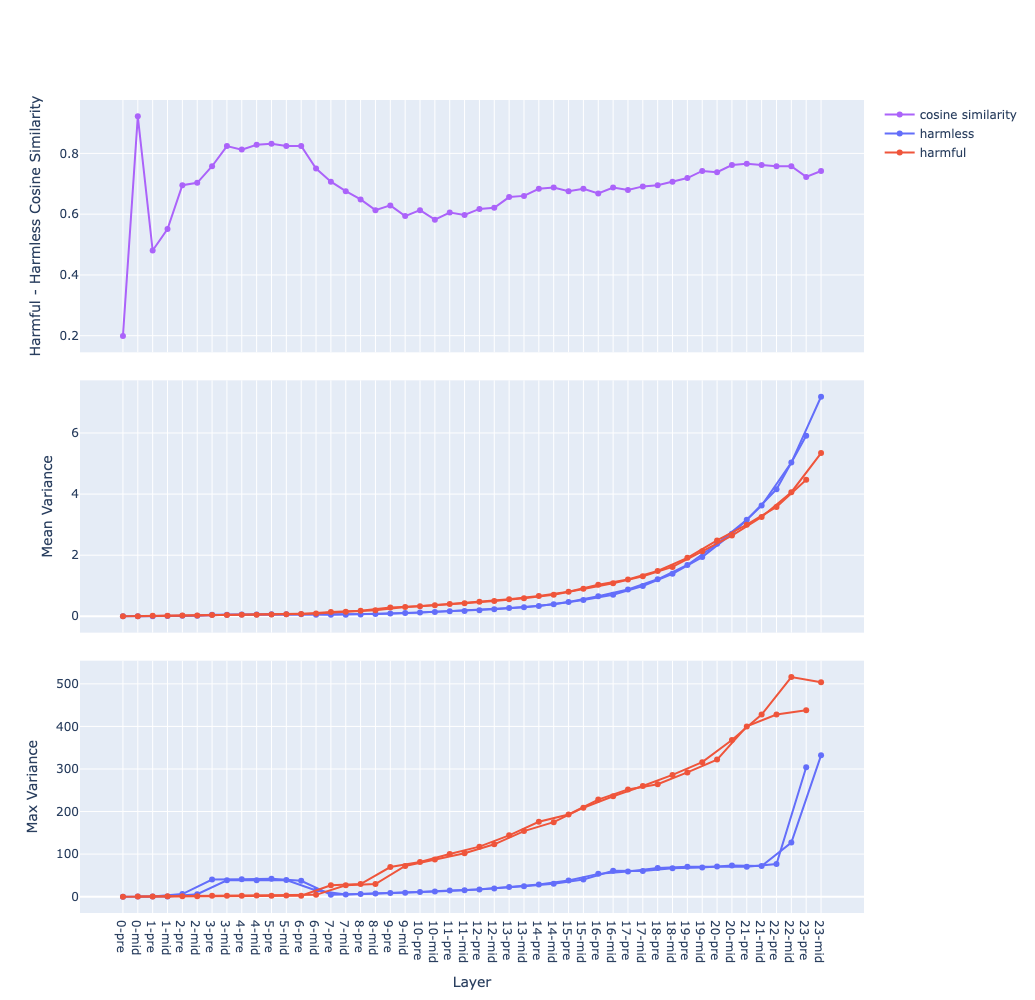
- this might suggest that instruction fine-tuning introduces behaviour vectors to the model hypothesis
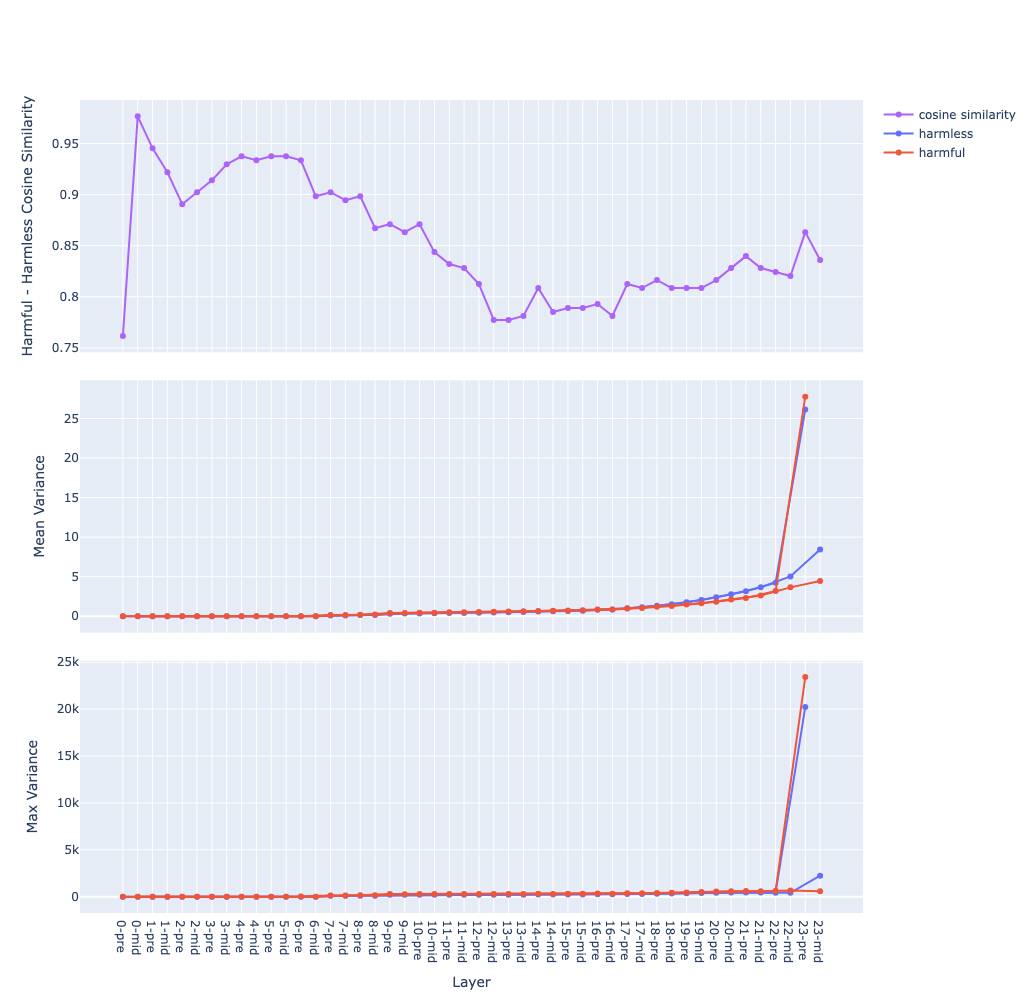
- but by just adding a newline character at the end, it will have a not as good but similar effect to using a template
How to find the refusal direction ?
Interpreting the refusal direction
- does it represent the refusal behaviour or harmfulness or both ? question
Thoughts
- Refusal direction is not the same as harmful-harmless direction
- The perpendicular direction to the refusal axis in case seems to represent a different but related concept, some possibilities are: usefulness, harmfulness, ethicalness question
- it’s likely that it’s does not contain this “other” concept but instead just overlap strongly
vector arithmetic or rotation ?
- Does only the direction matter or the magnitude as well ?
- recent works seems to consider both
- they operate on the pre-normed activation
- But modern LLMs use RMSNorm
Transclude of The-effect-of-BatchNorm-vs-LayerNorm-vs-RMSNorm#^53c1d6
- So the magnitude will aways be normalized before going into a MLP or Attention layer
- My hypothesis is: the feature varies its effect from a rotation on a 2D plane (could be higher dimension) around the complemented n-2 dimensional subspace hypothesis
- The magnitude, while matters for raw activations, is not important for varying the effect of a feature
- Scaling the magnitude is just a proxy for rotating the direction, and it can only mimic half of the rotation
- The directional magnitude of a feature in the raw activations is for competing with other features in superposition and reducing the interference of other features
experiments
on activation engineering and parameter engineering
- the idea of activation control seems similar to control net in diffusion models
- combining LoRAs in diffusion models work quite well but model merging in LLMs is not as good
- might be due to the fact that the parameter space of LLMs are non-Euclidean (Meta Curvature, CAMEx)
- does that means the parameter space of diffusion models are Euclidean ? question study
- parameter engineering (modifying weights) tends to work well on diffusion models whereas activation engineering (modifying activation values) tends to work well on LLMs. why ? question