What
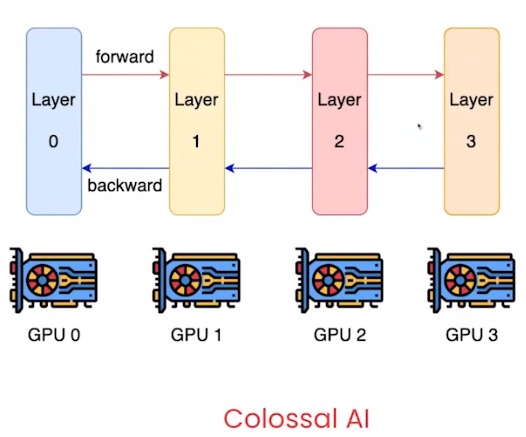
- have each layer of the network on a different GPU
- constantly sending data forward and backward through the GPUs
Hence
- a very complicated strategy
- very scalable
- bubbles (low utilization):
- all other GPUs is idle when the 1st batch is in the 1st GPU
- the GPUs become idle as the last batch is passed through
- need to do a lot of data before this makes sense because these bubbles cause cost a lot of utilization