DocQA¶
![]()
![]()
Ask questions on your documents.
This repo contains various tools for creating a document QA app from your text file to a RAG chatbot.
Installation¶
- Get the source code
- It is recommended to create a virtual environment
- First, let's install Marker (following its instructions)
- Then install docqa
Demo¶
This repo contains a demo for the whole pipeline for a QA chatbot on Generative Agents based on the information in this paper.
For information about the development process, please refer to the technical report
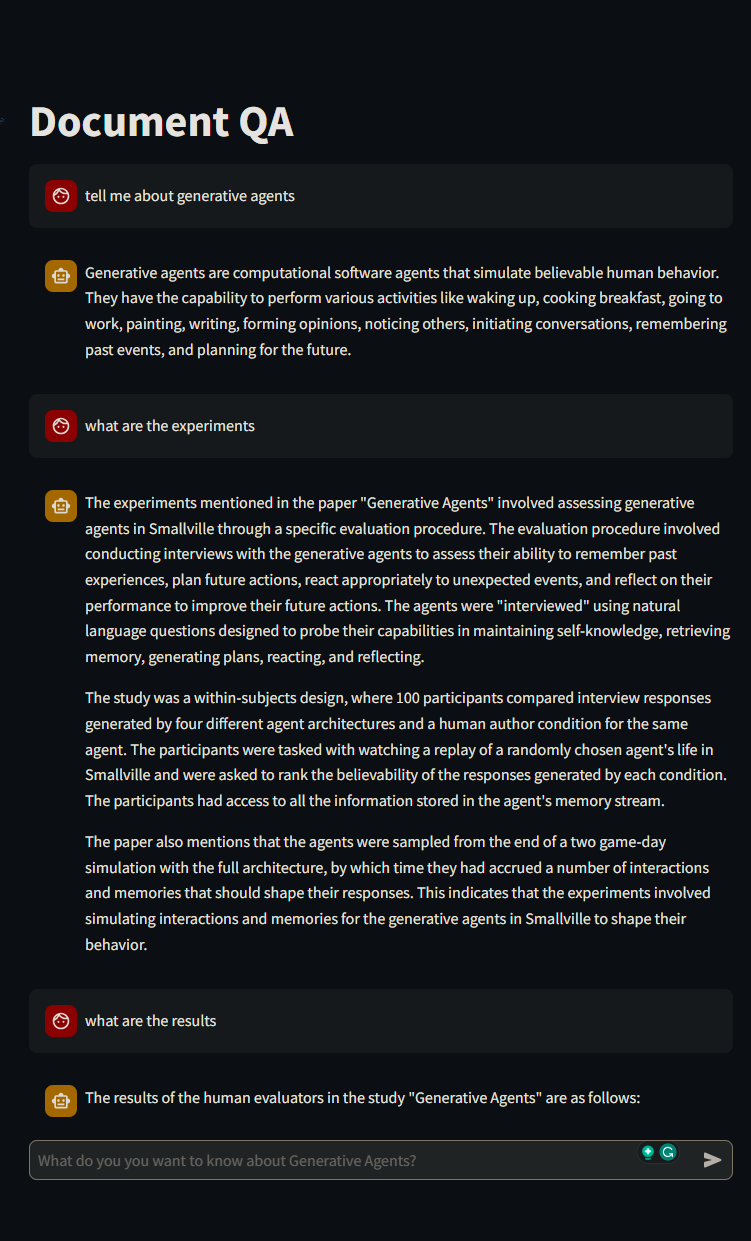
Try the Demo¶
From source¶
In order to use this app, you need a OpenAI API key.
Before playing with the demo, please populate your key and secrets in the .env file:
All the scripts for the full pipeline as well as generated artifacts are in the demo folder.
create_dataset.py: This script handles the full data processing pipeline:- parse the pdf file
- convert it to markdown
- chunk the content preserving structural content
- generate question-answers pairs
- prepare data for other steps: fine-tuning OpenAI models, and adding to vector-stores.
finetune_openai.py: As the name suggests, this script is used to fine-tune the OpenAI model using the data generated increate_dataset.py.- Also includes Wandb logging.
pipeline.py: Declares the QA pipeline with semantic retrieval using ChromaDB.
The main.py script is the endpoint for running the backend app:
And to run the front end:
Using Docker¶
Alternatively, you can get the image from Docker Hub.
Note that the docker does not contain the front end. To run it you can simply do:
Architecture¶
Data Pipeline¶
The diagram below describes the data life cycle. Results from each step can be found at docqa/demo/data/generative_agent.
flowchart LR
subgraph pdf-to-md[PDF to Markdown]
direction RL
pdf[PDF] --> raw-md(raw\nmarkdown)
raw-md --> tidied-md([tidied\nmarkdown])
end
subgraph create-dataset[Create Dataset]
tidied-md --> sections([markdown\nsections])
sections --> doc-tree([doc\ntree])
doc-tree --> top-lv([top-level\nsections])
doc-tree --> chunks([section-bounded\nchunks])
top-lv --> top-lv-qa([top-level sections\nQA pairs])
top-lv-qa --> finetune-data([fine-tuning\ndata])
end
finetune-data --> lm{{language\nmodel}}
top-lv-qa --> vector-store[(vector\nstore)]
chunks ----> vector-storeApp¶
The diagram below describes the app's internal working, from receiving a question to answering it.
flowchart LR
query(query) --> emb{{embedding\nmodel}}
subgraph retriever[SemanticRetriever]
direction LR
vector-store[(vector\nstore)]
emb --> vector-store
vector-store --> chunks([related\nchunks])
vector-store --> questions([similar\nquestions])
questions --> sections([related\nsections])
end
sections --> ref([references])
chunks --> ref
query --> thresh{similarity > threshold}
questions --> thresh
thresh -- true --> answer(((answer &\nreferences)))
thresh -- false --> answerer
ref --> prompt(prompt)
query --> prompt
subgraph answerer[AnswerGenerator]
direction LR
prompt --> llm{{language\nmodel}}
end
llm --> answer
ref --> answer